Why personalisation projects fail – and how to set yours up differently

Personalisation has been on the digital agenda for a long time. Most digital teams have either attempted it, been sold it as part of a platform upgrade, or inherited a roadmap item that's been sitting untouched for several years. The idea isn't new, and neither is the frustration.
So why does personalisation keep appearing in strategies and disappearing in practice?
The problem rarely comes down to ambition or expertise. More often it comes down to how personalisation projects get set up and the assumptions baked in from the start.
The project that never gets off the ground
The most common personalisation failure happens before a single rule is written.
Teams approach personalisation as a major strategic initiative. There are workshops to define audience segments, data audits to assess what's available, and conversations with the legal team about consent frameworks. Someone commissions a discovery phase. A consultant is brought in to map the customer journey. A presentation is made to senior stakeholders, who ask for a business case before signing off on the next stage.
By the time the groundwork is laid, the project has consumed weeks of resources, involved people from half a dozen teams, and generated a lot of documentation. But nobody has personalised anything yet.
This is the over-engineering trap, and it's easy to fall into because personalisation feels like it should be complex. Many vendors who sell it have spent years positioning it as a sophisticated, data-driven capability requiring significant investment to do properly. The case studies they share often feature elaborate, multi-stage audience journeys. The implication – sometimes explicit – is that anything less ambitious isn't really personalisation at all.
That does real damage because it sets a bar that most digital teams can't clear without significant time and resources, and it makes starting small feel like starting wrong.
Most of the groundwork that precedes a personalisation project doesn't actually need to be finished before you begin. Audience definitions get sharper once you have real data to work with. Consent frameworks are much less of an obstacle when you're not relying on cookies or invasive tracking. And a business case is far easier to make once you have something running and can point to actual outcomes.
Momentum doesn’t stall because teams lack the skills to make personalisation work, but because the project is designed in a way that makes getting started as hard as possible. By the time the foundation is ready, other priorities have taken over, and the initiative quietly moves back to the roadmap.
A better project plan won't fix this, but a smaller starting point will.
Starting with the wrong question
A lot of personalisation approaches assume you need rich first-party data before anything meaningful can be done. CRM integrations, behavioural profiles, and authenticated user data are all genuinely useful, but also a significant barrier if your team doesn't have them ready to go.
This assumption tends to come from the same place as the over-engineering trap. Platform vendors position personalisation as a data-driven capability, and the more sophisticated the tool, the more data it implies you should be feeding into it. Teams absorb that framing and conclude that their data infrastructure needs to be in order before personalisation can begin.
So, they start auditing. What data sources do we have access to? What's available from the CRM? Can we get behavioural data out of the analytics platform? Is our consent framework robust enough to support this? These are reasonable questions, but asking them before you've defined what you're actually trying to personalise puts the cart firmly before the horse. You end up assessing data you may never need, against requirements you haven't yet defined, for audiences you haven't yet identified.
Many teams get stuck in this loop indefinitely, waiting for a data layer that either never arrives or requires a level of technical investment that's hard to justify without first demonstrating value. A more useful starting point is to flip the sequence entirely. Begin with the user journey, identify the specific group of people you're trying to serve differently, and work backwards to ask what data you'd need to recognise them. That question is almost always much easier to answer than "what can we do with all the data we have?"
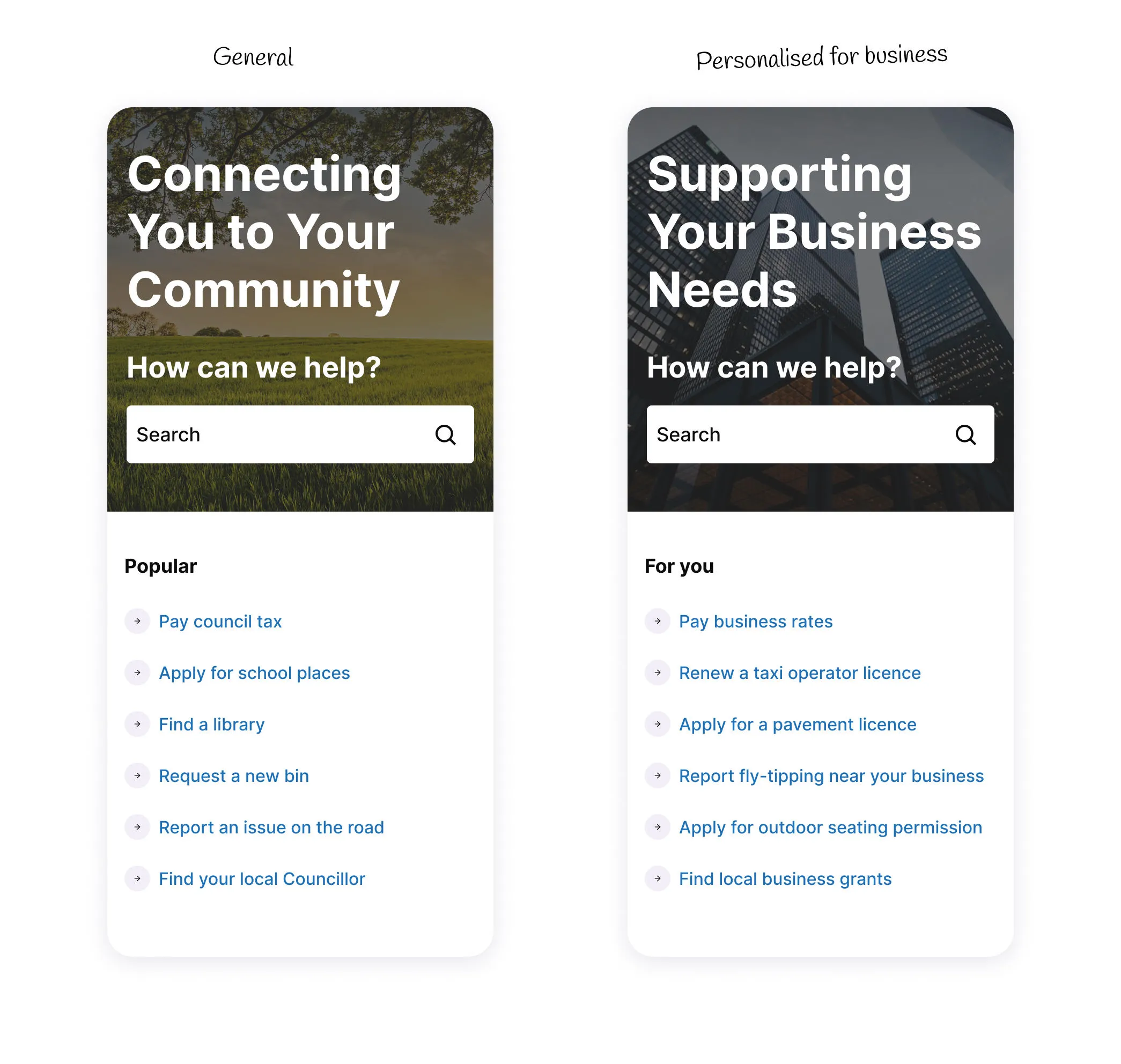
In practice, the signals you need are often already available. A visitor's location, their referral source, the device they're using, the pages they've viewed in the current session – for a university wanting to show different content to prospective international students, that's already enough to get started without a CRM integration or a consent overhaul. The signal that tells you which group a visitor belongs to is usually simpler than teams assume, and starting with a specific use case forces you to find it rather than spending months cataloguing data sources that may never be relevant.
When personalisation needs a developer
Even teams who have clear content ideas and a willing strategy often hit a wall when it comes to implementation, and that wall is usually the development queue.
In many organisations, personalisation ends up sitting in a separate layer from the CMS. This isn't always a deliberate choice. It tends to happen because personalisation was added to a platform that wasn't originally designed to support it – bolted on through a vendor acquisition, a third-party integration, or a tag manager workaround. The result is that content teams find themselves working across two systems rather than one and any change to personalisation logic means involving teams and systems that content editors might not have access to.
The practical consequence is familiar to anyone who’s worked in this environment. You have an idea, such as showing a different banner to visitors arriving from a specific campaign or surfacing a different call to action for returning visitors, and the first thing you have to do is write it up as a ticket. Then you wait for it to be prioritised against everything else the development team is working on. By the time it's built, tested, and deployed, weeks may have passed and the moment has often moved on.
That cycle doesn't just slow things down. It gradually drains the enthusiasm of the people who are supposed to be driving personalisation forward. Content teams stop generating ideas because they've learned that ideas don't go anywhere quickly. Personalisation becomes something that happens in planned releases rather than in response to real user behaviour, which is precisely the opposite of what it's supposed to be.
Part of the reason this problem is so persistent is that it's architectural as much as organisational. Many traditional platforms deliver personalisation server-side, meaning the decision about which content to show a visitor is made on the server before the page reaches the browser. That ties personalisation logic to the infrastructure layer, which means changes to rules can affect how pages are assembled and served, making personalisation a developer concern.
When personalisation is built into the content model rather than layered on top of it, and when the logic runs in the browser rather than on the server, content teams can manage their own rules without touching the underlying infrastructure at all. The developer dependency doesn't disappear entirely, initial setup still requires technical work, but the ongoing management of personalisation becomes a content team responsibility, which is where it belongs.
Nobody owns it
Personalisation tends to fall between teams. Marketing owns the audience strategy but not the technology. Developers own the technology but not the content. Content teams own the content, but not the rules that determine who sees what. In most organisations nobody has a clear mandate to bring all of that together, and without one, nothing moves.
This isn't a reflection of how well a team is organised. It follows directly from the way personalisation typically gets built. When it lives in a separate layer from the CMS, bolted on rather than built in, it doesn't belong naturally to anyone's existing workflow. Content teams work in the CMS. Developers work in the infrastructure. Personalisation sits in the gap between the two, and the gap is where initiatives get bogged down.
The way personalisation gets purchased can make this worse. It's typically signed off at a senior level, as part of a platform upgrade or a broader digital transformation programme, and then handed down to teams who weren't involved in the buying decision and have no formal remit to run it. The capability exists on paper. Someone demo'd it in a sales presentation. But nobody was ever explicitly given the job of making it work, and in the absence of a clear owner it defaults to being everyone's responsibility – which in practice means no one drives it forward.
The consequences are probably familiar. Content gets created but never connected to a rule because the person who built it assumed someone else would configure the logic. Audiences get defined in a workshop and never implemented because the team that ran the workshop doesn't have access to the tools. In lean digital teams the situation is even more acute – personalisation requires sustained attention across disciplines to gain momentum, and it's exactly the kind of initiative that gets deprioritised when everyone is already stretched. It becomes the thing everyone agrees is important but nobody has the time or energy to take on.
Assigning a clear owner helps, but the more durable fix is reducing the number of teams that need to be involved in the day-to-day running of personalisation in the first place. When content teams can manage their own rules without raising a ticket, and when personalisation logic lives inside the same system they already use to manage content, the ownership question becomes much easier to answer.
Measuring the wrong things too soon
When teams do get a personalisation project off the ground, there's often pressure to show results quickly. Given that personalisation is frequently signed off at a senior level, as part of a platform investment or a broader digital transformation programme, that pressure is understandable. The leadership team has approved the budget and wants to see the return. As a result, the people running the project often reach for the most visible metric available.
That metric is almost always conversion. And when conversion uplift doesn't materialise in the first few weeks – which it rarely does – confidence drops, questions get asked, and the project starts to feel like it isn't working.
The problem is that conversion is too far along the journey to tell you much at this stage. Between a visitor arriving on your site and converting, there are a dozen smaller decisions and interactions. Personalisation affects those earlier moments – whether the visitor finds what they're looking for, whether the page feels relevant to their context, whether they engage more deeply rather than bouncing. None of that shows up immediately in conversion data, and trying to read it there too early will almost always produce an inconclusive result.
What actually tells you whether early personalisation is working are engagement metrics – time on page, scroll depth, click-through rates on personalised content, return visit rates, and task completion where it can be measured. These aren't glamorous numbers, but they tell you something real about whether the experience you've created is more relevant than the default. That's what you're trying to establish at this stage, not whether revenue has gone up.
When teams reach for conversion data too early and find it inconclusive, they tend to lose confidence at exactly the point where they should be iterating. A personalisation rule that's been live for three weeks hasn't had time to generate meaningful conversion data, but it may already be showing positive engagement signals that – with a few refinements – would eventually translate into the conversion uplift the leadership team is looking for. Abandoning it at this stage, or using the inconclusive data to argue that personalisation doesn't work, means throwing away progress and reinforcing the cycle of stalled initiatives.
This is another reason why starting with a single, well-defined use case matters. Measuring the impact of one personalisation rule on one user journey is manageable. You have a clear baseline, a specific audience, and a defined set of success criteria. Trying to measure the impact of a broad personalisation programme across multiple audiences and journeys simultaneously is much harder, and much more likely to produce the kind of ambiguous results that make it easy to conclude that nothing is working.
Start smaller than you think you need to
All of these problems have something in common. They're features of how personalisation has typically been approached – as a large, infrastructure-heavy programme that requires everything to be in place before it can begin.
The teams that make personalisation work tend to approach it differently. Rather than asking "how do we personalise our website," they ask a more useful question – where does our site most obviously fail to serve a specific, identifiable group of people?
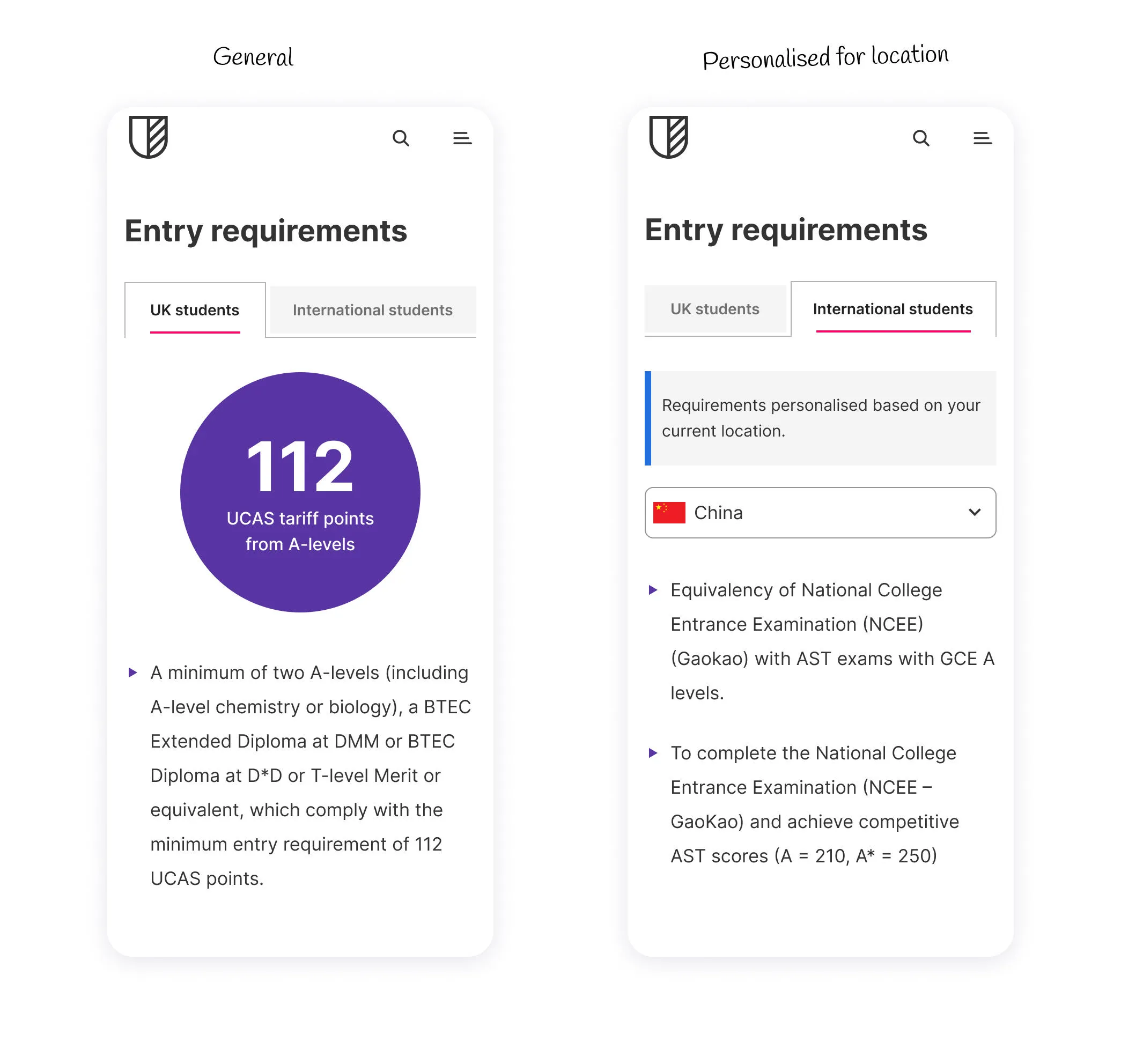
The answer is usually obvious once you ask it. A university homepage that treats prospective international students and current students identically. A council website that makes residents and businesses wade through the same navigation to find completely different services. A landing page that shows the same message to a first-time visitor and someone who has already spent time researching a specific course. Each of these is a journey where a single, well-chosen personalisation rule would make a noticeable difference.
Picking one of those journeys and solving it properly is a more effective strategy than attempting to personalise everything and finishing nothing. Think of it as a minimum viable approach – identify the user journey where personalisation will have the most impact, get something live, measure whether it's working, and build from there. The data and internal credibility you generate from one successful use case will do more to advance your personalisation programme than any amount of upfront planning – and each use case teaches you something about your audience, your content, and your team's capacity to manage personalisation at scale, making the next one easier to plan, faster to implement, and easier to justify.
The technology to support this way of working exists. The question is whether your team is set up to use it in a way that actually sticks, and whether your approach to getting started gives you a realistic chance of building momentum rather than running out of it.
Check out the next blog in this series, where we look at how to choose that first use case – and how to get something live without months of groundwork first.


